
开篇废话
之前博客的供应方跑路了,差点连数据都没剩下,为了方便把以前写的全部总结到一篇,基本都是和渲染有关的,更多可能是实时渲染方面的。文内有的链接可能已经过时。
注意,最近一年比较忙没怎么关注实时渲染,某些东西可能已经过时!
几个算法
Interactive Indirect Illumination Using Voxel Cone Tracing
这是一种实时的方法,可以支持动态场景,虚幻4之前就实现过这种方案,效果不错,但是效率还是差点。这个大致看起来很简单的方案,但是实现上细节还需要一些时间来处理的。 这个算法用原文的话来说就是三步:
- 体素化场景,从动态光源把光照信息写到叶子节点去
- 过滤这些值,其中某些值比如法线就用NDF分布
- 最后渲染场景,对点进行cone追踪
细节上,关于体素渲染的在这篇讲了一些理论基础,然后这里再说一些必要的细节: 首先,体素化场景,体素化场景使用稀疏八叉树来体素化,实现上用一个GPU线性内存实现了一个八叉树node池,体素数据储存到了一个叫做brick map的3D纹理中,姑且叫做brick池。八叉树池里面存的八叉树节点,每个节点有下列数据:
- 如果是内节点
- 是否叶子节点标识
- 是否终结标识(有的节点是常节点或者空节点,这些节点里面没有数据,只是为了维持八叉树性质存在)
- 子节点地址(作者为了压缩数据提高cache一致性把同一节点的所有子节点并列放在一起,所以一个指针就够了)
- 如果是叶子节点
- 如果是常节点或者空节点
- 常量颜色
- 如果是数据叶子节点
- brick map地址(3D纹理坐标)
- 如果是常节点或者空节点
在GPU上,这些数据总共用了两个32字节来储存。 brick map中放的是并列的brick也就是一个空间实体,里面填充了很多小的体素网格,一般是$N^3,N=8$。这么分叫做八叉树自适应分辨率,对应于brick自适应分辨率,这个都是题外话了。这么做的原因大概是下面这些:
- 可以灵活调节分辨率
- 有足够的精度来做过滤,一个体素怎么过滤啊喂!
- 提硬件升纹理采样精度
运作过程大概是这样的:
- 首先建立稀疏八叉树,把整个空间分为八份,一直递归地分直到深度合适,然后拿三角形去和叶节点求交,如果有交点,就创建一个brick,把这个brick分成$N^3$份作为体素,然后和这些体素求交,把相交的部分的参数(法线[法线记得写成高斯分布参数]着色参数什么的)填写到对应的体素里面去,没交的不要填,这样把所有的叶子节点对应的brick都填好;(在现代GPU上建立八叉树的方法可能和这里不同,我是看的【2】里面的CPU算法,GPU这方面的资料很多)
- 现在所有的叶子节点都有体素数据了,于是就可以一层一层地网上过滤了,这种每个节点分为$N^3$个的,每个子树只分到$\frac{N^3}{8}$个,所以就是每个叶子节点集中的八个合成一个父节点的体素就可以了,一直网上过滤,直到root。
- 现在为止,整个八叉树已经建立好了。然后做cone跟踪,从光线发射位置开始根据自身的相对节点的位置,一层一层地往下遍历树,直到被遍历到的那个node中的体素尺寸比像素小为止(每次往下走的时候尺寸除以2,最后是计算体素尺寸所以还要除以一个8再转换到屏幕上和像素尺寸做比较,另外要记录父节点)。这个遍历很容易做,只要有当前的位置就可以通过结算节点中的相对位置一层层往下走。
- 这个时候有了一个确定的层级位置了(因为当前层和父层都有了),这个时候就使用当前的位置在两个节点对应的brick中查找着色参数了,然后再把两个查出来的值(查询纹理是个硬件操作),在两个层级之间做一个线性插值,最后就得到了最终这个点的着色参数,这一步就是所谓的四线性插值。(为什么是四线性插值呢,看了前面一篇讲体素渲染的就知道,我们在体素中储存的东西都是预积分,这个积分有四个变量位置p,光线方向d,面积s,步长l,本来不是线性关系的,但是为了简化就搞成了线性关系,另外还把s搞成了$s=l^2$那么这里就只剩下3个值了,这三个值在3D纹理中可以直接做三线性插值,也就是前面查值,然后剩下一个层级间的插值,加起来就是四个变量的函数了,所以是四线性插值。)
- 至此,已经可以成功着色了;那么下一步就是让光线步进,根据奈奎斯特采样定理,这里至少要在一个体素里面采样两次才能正确重建信号,所以一个沿光线的一个步长至少一个当前层级体素的尺寸,到了下一个点就继续上面的步骤。
- 当然在执行过程中还有两种情况就是,层级上升和终止。以后空了再细说吧。
- 到这里当然还没完,这里要做全局光照,肯定要做bounce的,方法很简单,把上面的方法拿来用延迟着色的方法做最终聚集就好了(具体就是以那个点为视点在周围适当做cone追踪),当然这个方法原来论文还提到怎么做AO方法都差不多,这里就不多说了。
参考文献
- 【1】GigaVoxels:A Voxel-Based Rendering Pipeline For Efficient Exploration Of Large And Detailed Scenes
- 【2】An Irradiance Atlas for Global Illumination in Complex Production Scene
- 【3】实现参考
辐射度算法
辐射度算法是使用有限元手段来解算渲染方程,主要能够hold住漫反射项。 主要的思想是,把每一个场景的的patch都看成一个光源,然后对于每个patch都聚集整个场景的辐射度,然后辐射出。这么做一遍之后相当于算出了直接光照,然后再来一个pass把直接光照过的场景作为光源再如第一个pass算一遍,如此反复,最后可以得到很好的结果。 有几个问题:
- 无法处理高光
- 对点光源效果差
- 场景要参数化
古典辐射度算法:
- 细分surface为patch
- 建模patch之间的光线传输为线性系统
- 重要假设
- 反射和发射都是漫反射(漫反射在所有方向反射均等,因此辐射度独立于视角)
- 无真空介质
- 无透射
- 辐射度across每一个element变化是常数
- 分离地计算RGB
能量平衡: 假设Lambertian表面,表面被分为n个element 有: $A_i$ element i的面积(可计算) $B_i$ element i的辐射度(未知) $E_i$ elment i的辐射流强度(给定) $\rho_i$ element i 反射率(给定) $F_{ji}$ j到i的Form factor(可计算)
方程本身很简单,是离散辐射度方程。
Form Factor(也称为View factor、configuration factor、shape factor)是光离开i到达j的传输因子,决定于
- ij patch的形状
- ij的相对朝向
- ij的距离
- 是否被Occluded
为了更好地理解这个量,我们说 简单地说,Fij就是辐射度离开表面i到达表面j的分数。 因为能量守恒,所以所有流出的factor最后要归一。 同时具有Reciprocity:
https://en.wikipedia.org/wiki/View_factor https://en.wikipedia.org/wiki/Radiosity_(computer_graphics) http://www.siggraph.org/education/materials/HyperGraph/radiosity/overview_2.htm https://www.academia.edu/738011/The_Radiosity_Algorithm_Basic_Implementations http://graphics.cs.cmu.edu/nsp/course/15-462/Spring04/slides/16-radiosity.pdf
这种方法深入来说是比较复杂的,在娱乐级渲染中,我知道的用得较多是有PRT(预计算辐射度传输【2】【3】),更多详细的有限元辐射度方法可以参考【1】.
参考文献
- 【1】Michael.F.Cohen John R.Wllace. Radiosity and Realistic Image Synthesis.1995.Academic Press Professional
- 【2】Precomputed Radiance Transfer for Real-Time Rendering in Dynamic, Low-Frequency Lighting Environments
- 【3】http://www0.cs.ucl.ac.uk/staff/j.kautz/PRTCourse/
混合和透明物体渲染
之前一直没有很仔细的地思考过Blend这个概念,唯一的映像就是$C_o = C_sAlpha+C_d(1-Alpha)$。所以在软件渲染器中也只是理论上支持这个东西,但实际上却只做了深度测试。现在来仔细看一看这个玩意儿,也记录一下透明物体渲染的东西。
Blending
这部分主要参考DX11龙书Blending一章。
简单的说,Blending就是使当前颜色作为混合源$C_s$不要直接覆盖前面一个颜色$C_d$,而是和前面的一个颜色混合起来,所以叫做混合。这个有助于渲染透明物体(当然这只是其中一种,只是我们目前最关注这一种而已)。当然对物要求也是有顺序的,所以在投入片元的时候要求渲染保序。
在D3D中混合方程如下:
其中$C_s、C_d$是参与混合的源颜色,和混合目标颜色,$F_x$则是混合函数。$*$是逐项乘符号,$@$则是任意运算符号。
在D3D11中,他可以使最大最小加减反减等等。
D3D11中对颜色的RGBA分开设置混合符号和混合函数,RGB为一个,A为一个。可以参考下列代码,这应该是配置Blending选项,然后再OM阶段进行混合。
D3D11_BLEND_DESC blendStateDescription;
ZeroMemory(&blendStateDescription, sizeof(D3D11_BLEND_DESC));
// Create an alpha enabled blend state description.
blendStateDescription.RenderTarget[0].BlendEnable = TRUE;
//blendStateDescription.RenderTarget[0].SrcBlend = D3D11_BLEND_ONE;
blendStateDescription.RenderTarget[0].SrcBlend = D3D11_BLEND_SRC_ALPHA;
blendStateDescription.RenderTarget[0].DestBlend = D3D11_BLEND_INV_SRC_ALPHA;
blendStateDescription.RenderTarget[0].BlendOp = D3D11_BLEND_OP_ADD;
blendStateDescription.RenderTarget[0].SrcBlendAlpha = D3D11_BLEND_ONE;
blendStateDescription.RenderTarget[0].DestBlendAlpha = D3D11_BLEND_ZERO;
blendStateDescription.RenderTarget[0].BlendOpAlpha = D3D11_BLEND_OP_ADD;
blendStateDescription.RenderTarget[0].RenderTargetWriteMask = 0x0f;
g_env->d3d_device->CreateBlendState(&blendStateDescription, &m_alphaEnableBlendingState);
具体的用法不是重点就不说了,查文档就知道了。
一般来说,混合只管RGB值而不管A值,除非在back buffer中A有特别的用途。
透明物体渲染
Blending渲染
混合可以做很多事情,但是这里只关注透明物体渲染。公式就是我最开始写的公式。只是在使用公式混合之前要对他们全部按照由远到近排序,然后从后往前绘制,而且在绘制所有透明物体之前必须先绘制所有不透明物体。这种从后往前的方法叫做OVER Blending。
这种混合操作有各种稀奇古怪的优化,比如在D3D11Shader中使用clip函数等,这个函数可以导致指定的像素在结束shader之后直接跳过OM阶段省事不少,所以在alpha接近0的时候就全部discard掉。
Using a DISCARD instruction in most circumstances will break EarlyZ (more on this later). However, if you’re not writing to depth (which is usually the case when alpha blending is enabled) it’s okay to use it and still have EarlyZ depth testing!
还有一种就是使用一个低的分辨率(一般一半)来渲染目标做混合的。
另外还有一种叫做UNDER Blending的从前往后渲染的方法。这种方法把公式拆为
$A_d$初始化为1.0。
最后,需要把算出了的颜色和背景颜色$C_{bg}$混合:
OIT
传统的ODT透明物体渲染方法一般是先渲染不透明对象,然后对透明的对象按照深度排序,然后进行渲染。这种方法对于交叉物体的渲染是有问题的。为了处理更一般的透明物体渲染,就要使用OIT方法。
下面有几个实时方法:
depth peeling[1]
渲染正常视图,将这一层深度剥离,渲染下一层深度的视图,以此类推。渲染每一个深度的图像,然后把所有的深度渲染结果混合起来。
这是一个多pass算法,具体的pass数和场景最大的深度复杂度有关。
还有一种拓展是Dual Depth Peeling[2]。这种算法在一个pass内剥离最近和最远的两个深度,如果有中间深度就按照规定来处理。最后对于这两种剥离,分别使用OVER和UNDER的blending方法来进行blending。
Per-Pixel Linked Lists[3]
这种方法利用SM5.0(这算是一个限制吧)的structured buffers和atomic operations[4]来建立每个像素的链表,然后对链表进行深度排序,最后按照排序结果使用Ray Marching方法来进行渲染。
下图大概说明了这种算法:


Start Offset Buffer对应于每个像素,存放链表头。
Fragment and Link Buffer是屏幕的n倍大,每个fragment的辐射度,体积衰减系数,物体的反照度,朝向信息,摄像机距离等数据都会打包成一个Structed Buffer然后扔到Fragment and Link Buffer中,这些单独的structed buffer用一个成员储存Fragment and Link Buffer中的索引链接下一个structed buffer。具体的可以参考这个slider[5]。 排序原论文通过权衡考虑使用的插排。
这个算法的理论性能比Depth peeling高一些,因为后者要N个pass所有pass都要处理所有的fragment,而这个算法只要一个pass就可。但是,Fragment and Link Buffer的大小无法事先比较精确的控制,这可能会导致空间浪费或者溢出。
值得注意的是:这种类似的方法产生的数据(这里的链表)涵盖整个场景的信息,我们可以使用这些数据来做很多事,比如:体素化甚至光线跟踪。
Ref
- 【1】Interactive Order-Independent Transparency
- 【2】Order Independent Transparency with Dual Depth Peeling
- 【3】Order Independent Transparency with Per-Pixel Linked Lists
- 【4】[Structured_Buffer]:https://msdn.microsoft.com/en-us/library/windows/desktop/ff476335(v=vs.85).aspx#Structured_Buffer
- 【5】Oit And Indirect Illumination Using Dx11 Linked Lists
AO
实时渲染里面相当重要的模拟GI的技术。
SSAO
AO Daekening因子$k_A$计算: 这个值在0~1之间,0代表完全遮蔽,,1代表完全可见。 最终的环境光照值: 在实时中的计算方案:
- 对象空间 - 光线投射相交几何体 - 这种方案慢,需要空间数据结构 - 取决于场景复杂度
- 屏幕空间 - 在post-pass做 - 没有预处理需求 - 和场景复杂度无关 - 简单 - 没有物理准确性
一种方案就是使用z-buffer来做ssao。 只要着色点周围有点,那些点就会遮蔽光,从而产生AO贡献。在着色像素的周围一个半径为R的球内采样,采样点然后转换到屏幕位置获得对应的像素深度,如果深度大于采样点,则此点贡献AO,否则直接扔掉,如果有一半的点都贡献,则apply AO. 关于采样,采样越多越精准,一般16个,可以用随机化纹理,使用保边过滤。
缺陷是:深度图带来的场景信息本来是不完整的,被其他对象遮蔽的点永远不会贡献AO,因为他的深度始终小于此着色点深度。
Reference
- ShaderX 7 6.1 SSAO
HBAO
这种方案也是在SS做,使用近似的ray trace深度buffer。
实现要点
需要法线已知,只在法线半球采样。
在视线方向(也就是深度平面的垂直方向)建立一个切平面(深度平面),在这个深度面上旋转一周来对每个方向求ao。
对每个方向求ao的方式是求切平面上当前方向向量和深度平面的角度,得到$t(\theta)$【这里的$\theta$是深度平面的旋转角】,然后在这个方向步进(ray martch),迭代出最大的仰角$h(\theta)$(具体方式是把平面坐标重建出view空间中的3D坐标,z就是深度),然后按照$sin(h) - sin(t)$乘以一个衰减系数然后全部加起来就是最终的ao值,最后为了是这个值不会超出范围,要区平均数归一化.1-这个值就是最后的环境光着色值.

其中法线buffer不要插值法线,要面法线。插值法线会造成错误的AO,因为插值的法线和深度buffer不匹配。 还有一个低细分问题,因为深度的精度不够导致曲线直接变成了直线:

这个可以通过加一个$\theta$ basis来解决:


AO间断问题:

这个使用一个衰减函数来解决:


原理
算环境光的公式是:
按照上面实现中说的坐标,把这个公式用球坐标积分出来。
可见度处理时,因为只有在$t(\theta)$和$h(\theta)$之间的那些角度才可见,其他部分的积分结果都是0,所以最后在球坐标下的积分结果变为:
最后W使用一个线性衰减函数$W(\theta)=max(0,1-r(\theta)/R)$,$r(\theta)$是点P和水平采样点在$\bar{\omega}$方向的距离,R是影响半径,这样的话,积分变为:
注意上面的那个$cos(\theta)$是积分变换出现的结果,$d\omega=cos(\alpha)d\theta d\alpha$
最后,把中间的积分直接算出来,就是最后结果了。
Reference
- Image-Space Horizon-Based Ambient Occlusion
SSDO
这种方法不仅仅是做AO,据原文他主要有两种效果——细节更加丰富的环境光&颜色blending。
总的来说,方法感觉很不错,但是一个满意的实现还是很繁杂(包括要使用深度剥离和多相机之类的来作为用深度做追踪的代价),主要还是因为SS没有完整的场景信息,SS方法这都是硬伤了。
这个算法需要两个buffer,一个法线信息,一个深度信息,分两个pass输出,第一个pass算直接光照,第二个pass用第一个pass的信息算bounces。
直接光照
通过下列方案来解耦遮蔽和着色计算:

先计算外面来的直接光照,使用一个标准分布来采样半球,每个覆盖一个solid angle:
最后这个光照计算出来就是这个公式:
入射辐射度$L_{in}$,可见性$V$,漫反射BRDF$\rho / \pi$
计算可见性方法如下:
使用一个从P到$\omega_i$的随机步长$\lambda_i \in [0…r_{max}]$。
其中$r_max$是用户自定义的半径。
采样结果就是以着色像素的重建3D点P为中心的随机采样位置$P+\lambda_i\omega_i$,很明显这些位置都在半球中,并且都oriented around法线n.具体的话就像上图左边那样。
一些点在集合体的内部,一些在外部,然后为了计算occluder,要把这些点反向投影到屏幕上去,最后考察这些点在投影中,对应的深度是比原来深了还是浅了(但是不要移动这些点本身!)。如图所示,比原来浅了的ABD就是在几何体下面的,这些点都是occluder,不要,只要C
然后我们只从非occluder方向计算直接入射光照
第一步作为一个pass,计算了直接光照。
间接光照
然后第二部做bounce。这是个one bounce算法。照例先上公式:
$d_i$是P和occluder i之间的距离(clamp到1),$\theta_{s_i}$和$\theta_{r_i}$是sender法线和receiver法线之间的夹角和传递方向的夹角。$A_s$是一个sender patch的面积,计算方法是:
假设这个半球的底部是平的,然后平分这个半球的基圆为采样数N那么多份,每份$A_s=\pi r_max^2 /N$,使用一个常数作为参数来调节半球底部的slope。他前面说的立体角是$\bigtriangleup \omega = 2*\pi / N$,但是求的半径不是1,所以,这里应该是在整个上半球采样的,后面的投射面积是个近似。那些点的分布处的面积是无法确定的,上半球壳的面积应该是
估计是因为本身要投影就用了基圆的面积来平分.
但此处问题不大,用一个参数可以调整的.
这样就可以计算出点的间接光照了
实现上,原文说用了一个MXN的纹理来储存采样点的位置参数
每个像素随即从M里面选一个sets出来
(这是生成的地差异序列,参考https://www.zhihu.com/question/24207493)

缺陷
这种方法到这里看来还是很好的,但是有几个缺陷,使其做起来并不那么令人满意。主要原因是因为本身这个算法是在ss中做的,所以并不是每一个间接光的blocker和source都是可见的。

如图所示,从左到右,bounce越来越弱,直到最后没有
上图左右
用人话说就是,第一次pass计算直接光照时候bounce的点是被计为occluder的,occluder就会投影,但是这种情况下法线却是向外的,因此,不会bounce。也就是说,这种方法只要出现了object之间的相互遮挡就会出现问题,后面因为遮挡还会出现不计算直接光照的现象。
问题就是场景信息的丢失,单深度纹理是有限制的
一种解决这个问题的方法是使用深度剥离,对于一个我们实时中用的模型,只要深度在连个相邻的深度图之间,那么一定在物体内部,也就是此点应该被归为occluder,否则就是可以被照亮的。
另外是使用多个摄像机
上面说的问题,还有一个
就是下图

左边的问题刚刚已经说了,剩下的就是右边的问题,被误照亮了,这个问题在hbao中也有,当时使用一个衰减函数来解决的,现在的解决方法是,在这个方向上等距离采样更多的点,只要有个点被判断为occluder,那么这个方向上的点就被判断为occluder了。单注意这里说的是环境光源下的情形。
几种实时渲染架构
Forward着色
主要有两种做法:
1、对场景渲染多遍,每遍计算一个光源信息 2、只画一遍,在shader里面处理多个光源的情况
但是换汤不换药,这样总是具有O(m*n)的复杂度。
它的主要缺陷是:
- 场景计算复杂度依赖于场景复杂度和光源个数
- 低效的光照culling,每个物体都要计算每个光照
- Shader经常需要超过一次以上的Pass来渲染光照,渲染n个灯光,对于复杂的Shader,可能需要O(n)次运算。(在延迟着色下,即使稍微复杂的shader也不需要多个pass。)
延迟着色
ref: http://blog.csdn.net/bugrunner/article/details/7436600 http://www.realtimerendering.com/blog/deferred-lighting-approaches/ http://www.klayge.org/2011/01/11/klayge%E4%B8%AD%E7%9A%84%E5%BB%B6%E8%BF%9F%E6%B8%B2%E6%9F%93%EF%BC%88%E4%B8%80%EF%BC%89/
延迟着色(光照)主要是:将光照、着色计算所需要的量使用一个单独的pass保存了下来,在以后的计算中再也不需要为了获取这些东西再去跑一个pass了!
Deferred Shading是一股脑儿将所有的Shading全部转到Deferred阶段进行,而Deferred Lighting 则是有选择地只将Lighting转到deferred中进行,两种方法的不同也就导致了算法的不同的特点及各自的优劣。
延迟着色
常见的光照着色方程,形式如下:
$B_{L_k}$为当前像素的处的光照密度或者颜色
$l_k$为当前像素处的光线向量
v是视线,n是法线,$c_diff$为当前像素的漫反射颜色,$c_spec$为当前像素的高光颜色,m为当前像素处的高光相关系数。
每个像素只需要对每个光源计算后相加就得到最终值。这些输入元素一般都在G-Pass完成计算,然后储存在G-buffer上,G-Buffer一般包含如下信息:
- 深度
- 法线和高光
- 漫反射率
- 高光反射率
- 发射光(Emissive)率
这些基本的,具体细节和详细组织还是和引擎相关。但是比如Depth,Normal,Diffuse,Specular都是必须的。有了G-buffer就可以在第二阶段Deferred Pass完成最终着色。
要储存足够的Gbuffer信息,使用一张渲染纹理显然是不够的,至少也要两张。如果不支持MRT的话,就需要多个Pass来计算,效率很低。但是有了MRT之后,GBuffer又带来了空间占用问题,所以就出现了延迟光照技术。
延迟光照(也叫作Light Pre-pass Rendering)
我们对原来的着色方程进行调整:
(这个调整视情况而定,根据具体的着色模型需要酌情更改) 根据这个方程,现在我们可以考虑使用延迟光照将漫反射和高光系数从G-Buffer中去除,只在延迟阶段计算光照。Diffuse与Specular分量在最终Shading阶段计算,所以DL相对于DS又增加了一个Pass。 延迟关照的主要流程是:
- 准备G-Buffer(Normal&Depth)
- 进行延迟光照得到L-Buffer(即计算上式中的$f_{diff}和$f_{spec}$$)
- 在L-Buffer的基础上重新渲染场景进行最终着色
优点
- 光照计算独立于场景复杂度
- 为了计算光照不再需要多pass了
- 场景管理和光照管理解耦
缺陷
- 这两种方法都不能渲染透明物体,所以要渲染透明物体必须使用新的pass来渲染。 对比参考http://gameangst.com/?p=141.
- 不支持MSAA。
Light Indexed Deferred Rendering
这个思想和典型的延迟着色是相反的——他储存光照属性(灯光方向、灯光范围等)到buffer上使用Forward着色进行渲染,而不是储存表面属性。
基本思考
考虑将灯光属性渲染到一个buffer上,考虑储存他的衰减后的灯光向量到每一个fragment,然后把每一个灯光在同一位置的向量求个和,使用以下公式:
我们的buffer能计算出左边的$(L_1+L_2+L_3)$,这些变量显然只和灯光有关,在着色的时候执行右边的操作即可得到着色结果。然而,问题在于,点乘法线的结果不能为负,所以统统要clamp到0.于是乎,左边算下来并不等于右边。如果想要保证结果正确就还是要访问fragment的法线,于是乎这本质上还是标准的延迟着色。并且,这种方法也不能hold住高光和其他光照模型。(仅仅对于各向同性材质友好。)
还有种方法就是可以储存灯光的方向、颜色、衰减,但是这么一来一个fragment久存不了多少灯光了,要么就是增多渲染目标或者buffer单个fragment的储存空间。
Light Indexed Deferred Lighting
新的方法就是不储存灯光的和材质属性本身,而是去储存每个灯光的索引。这个索引用于查询一个灯光属性table。
基本passes:
- 深度pre-pass
- 禁用depth-write(noly depth testing)、渲染光照体积(控制那些fragment被灯光覆盖)到一个灯光索引纹理中。(Standard deferred lighting / shadow volume techniques can be used to find what fragments are hit by each light volume.)
- 使用标准的Forward渲染几何体——使用灯光索引访问灯光属性来计算光照。
为了使得这个方法可以用于灯光重叠的情形需要使用一种方法来Pack灯光索引。
原文中提出了三种pack方法:这里就不一一说了,是在不行可以用MRT。。。
【1】Light Indexed Deferred Lighting,Damian Trebilco
Inferred Lighting一个新的思路
这是一个DL的改进,最终的效能并不如DL好,但是是一个新思路。
Inferred Lighting:Fast dynamic lighting and shadows for opaque and translucent objects
这种方案:
- 支持显著小于输出分辨率的buffer用于光照
- 兼容MSAA
- 主要使用了一种叫做discontinuity sensitive filering的算法,这允许材质shader在一个不同分辨率的光照buffer中推断(infer)出光照。
- 可以比较好的处理透明物体,不需要附加的pass
Tiled Shading
【Ola Olsson and Ulf Assarsson】
Tiled Deferred Shading
为了提升延迟着色的性能,需要cull灯光。某些方法对每种类型的灯光绘制代理几何体然后求交,而某些则使用近似的AABB布告板来近似模拟灯光范围,还有的方案则是绘制3D的代理几何体(比如球和圆锥)。这些实现似乎都是每个灯光一个pass,于是读取GBuffer多次成了一个问题。所以又出现了Tiled Deferred Shading。
优点
- G-BUffer(被指定灯光照亮的)只读取一次(纹理fetch和数据解包都只执行一次。)
- Common term可以冲渲染方程里面拿出来(material diffuse and specular colors, as these are the same for all lights)
- frame buffer只被写一次
- 光照计算结果在寄存器上累计全部都是float级别精度
- 相同tile中的fragment一致地处理相同的灯光
执行步骤
- 渲染不透明几何体到GBuffer。
- 适用固定尺寸(e.g.32X32)构造SSGrid
- 遍历灯光,找到光照体积相交的grid cell并把灯光ID append上去
- 遍历frambuffer中的每个fragment——1)采样(x,y)处的Gbuffer;2)累计(x,y)/(32,32)处tile中所有光照的贡献;3)储存光照到framebuffer的(x,y)处。 Note how the function does not depend on anything else; It can thus be called from either a deferred or forward fragment shader, or indeed a compute shader. In fact, there is nothing preventing it being used froma vertex shader either.
着色函数
vec3 computeLight(vec3 position, vec3 normal, vec3 albedo,vec3 specular, vec3 viewDir, float shininess,ivec2 fragPos)
{
ivec2 l = ivec2(fragPos.x / LIGHT_GRID_CELL_DIM_X,fragPos.y / LIGHT_GRID_CELL_DIM_Y);
int count = lightGrid[l.x + l.y * gridDim.x].x;
int offset = lightGrid[l.x + l.y * gridDim.x].y;
vec3 shading = vec3(0.0);
for (int i = 0; i < count; ++i)
{
ivec2 dataInd = ivec2((offset + i) % TILE_DATA_TEX_WIDTH,(offset + i) / TILE_DATA_TEX_WIDTH);
int lightId = texelFetch(tileDataTex, dataInd, 0).x;
shading += applyLight(position, normal, albedo, specular,shininess, viewDir, lightId);
}
return shading;
}
限制
内存消耗过大,GBufferAA,shadow map等。
Tiled Forward Shading
优点
- 光照与几何体管理解耦
- 光照数据可以每个场景一次性全部上传到GPU(传统的前向着色为了不让几何数据计算过多灯光,最小化灯光集上传,但同时有想要上传更多的几何体,从而造成了优化batch尺寸和最小化灯光数量的冲突。由于Tiled方法的解耦,batch优化可以单独优化,灯光于是可以一次性上传。)
- FSAA工作正常(传统的着色方法可以应用FSAA。)
- Common term可以从渲染方程中facroed out
- 寄存器浮点光照累计
- 与Tiled Deferred着色函数一样(没有Gbuffer的问题,集成到传统前想渲染也很简单。We also exploit this to support transparency.)
限制
每一个fragment可能会被多次着色(相同的fragment被多个primitive影响),这个问题可以简单地使用Pre-Z Pass来解决,如果光照不那么多也可以skip掉Pre-Z。FSAA开启的overshading问题。
处理透明
由于着色函数一样,可以先使用Tiled Deferred Shading渲染不透明物体,再使用Tiled Forward Shading渲染透明物体。两者具有高度的数据共享。
Ref
- Tiled Shading
- RefImp
- https://software.intel.com/sites/default/files/m/d/4/1/d/8/lauritzen_deferred_shading_siggraph_2010.pdf
- http://leifnode.com/2015/05/tiled-deferred-shading/
- http://pan.baidu.com/s/1dETjV0l
Clustered Shading
- http://www.cse.chalmers.se/~olaolss/get_file.php?filename=papers/tiled_shading_siggraph_2012.pdf
-
http://www.cse.chalmers.se/~olaolss/get_file.php?filename=papers/clustered_shading_preprint.pdf
- http://www.klayge.org/material/4_4/SSS/Colin_BarreBrisebois_Programming_ApproximatingTranslucency.pdf
一些细节
Z Pre-Pass
进行一个只有深度的pass(Z pre-pass), 用深度数据填充Z-buffer的同时完成Z剔除, 然后利用这些数据来进行光照, 避免了像素的重复绘制. 这个方法早已被硬件厂商用于改进他们的硬件设计.只渲染深度的话可以比颜色和深度一起写入快2-8倍.
ShadeTree
目前这部分主要还来自”Shade Trees,Robert L. Cook “,只是对基本概念的一个记录,有的理解也不一定正确,以后会随着实践的增多会慢慢修整补充。 我们现在看到的着色语言就是对Shade Tree的最直接应用,另外那些连线材质编辑器,比如UE4的材质编辑器都是shade tree的一个应用。 通俗的说,shade tree就是使用tree的形式来组织着色。增加了很多的灵活性。 每个树的节点产生一个或者多个参数,并且使用零或者更多的参数作为输入。这些node的作用就是做计算,比如“diffuse”用于漫反射计算,输入一个表面法线和一个光照向量,输出着色强度。这个法线可以来自几何体,纹理等等,也是一个node输出的,这个输出的强度可以作为一个“multiply”node的输出用来比如调制颜色。 原文中还提到了光照树和大气树,其实都是一样的原理。 于是,使用这样的方法建立一棵树,然后遍历一次,可以把对应的操作转化为shader程序,然后进行着色。 这是基本原理,更多的细节还需要在实践中获得。
光学光晕
极亮的光源造成眼镜内光线的衍射和散射造成了光源周围模糊的形状和条纹。
深度
默认情况下, 顶点经过mvp变换, 再单位化到NDC以后, 深度是非线性的, 其函数是一个(-) 1/(a + bx)的曲线, 导致靠近near clip plane的z值精度高, 远处精度低. 使用linear depth 以后深度变化都是均匀的.
linear depth通常使用view space的z 再除以max view distance即far clip distance得到单位化的z,这个z值可以直接写入zbuffer, 用于depth test, 不过需要所有的shader都输出linear depth才能正常使用, 除了那些不需要深度写和深度测试的对象, 可以不用修改.
这个linear depth也可以用于线性插值, 所以可以在vertex shader里面计算出结果, 在pixel shader里面输出到深度.
如果不用linear depth, 需要将NDC坐标unproject到world space, 即乘以 invViewProjection, 一次矩阵运算来得到world space.
因为shader一次会对多个像素做计算,所以动态分支会对所有代码都跑一边,最后根据分支写入结果,效率比较低。为了防止shader动态分支,一般采用静态分支编译成多个shader使用。
Pixel Shader中的position的z是非线性z值,之前在透视矩阵的时候我们使用基本几何知识推倒出有结果
此时z值如果没有深度测试时没有用的。
但是因为深度测试我们必须要保留z值,但是注意在PS之前三角形必须要插值,因为$x’y’$都已经除以了z所以可以直接$1/P_z$插值,然而直接传递z却并不能插值。所以必须把这个用于深度的z也做成$z’‘=a1/P_z+b$的形式以便可以正确插值。而根据插值前后的范围在[n,f]~[0,1],可以解出a/b。这时候我们可以得到的齐次坐标,最后一项设为w=1。
现在要从中抽取出透视矩阵,因为整个矩阵里面肯定不能包含xyz中的任何一个,所以抽取出来的矩阵只能把坐标[x,y,z,1]转换为[x’z,y’z,z’z,z].
注意,为什么要乘以一个z而不是一个Pi*z或是别的什么,因为这里出来一个z值在VS结束后的下几个阶段还有用。注意:并不是一出了VS就插值。
点被执行了透视矩阵后,直接进入clipping space,这个空间是没除以z(w)之前的空间,要在这里做裁剪(具体参考i三角形裁剪),前面已经说了,在这里裁剪是最好裁剪的地方,这个z就是用来裁剪了!
过了裁剪步骤,就会除以z(透视除法)以便插值进入PS,一旦除以w,就是NDC SPACE(Normalized Device Coordinates,就是全是[-1,1]那个空间).
线性深度
上面的过程可以看出,最后得出的0~1的深度其实是非线性的,他是一个指数函数
 解决线性深度有一个方案是使用wbuffer。把透视矩阵变为
2n/(r-l)
2n/(t-b)
f/(f-n) 1
-fn/(f-n)
这个矩阵类似于正交矩阵,实际上是利用了存在w中的z,做透视除法后对xy进行缩放来实现透视,但事实上他和上面透视矩阵是一样的,具体wbuffer到底是怎么实现的,怎样作用于管线我也不是很清楚,似乎现在这个技术已经被抛弃了,几乎没有什么资料。
还有一种log 深度的logarithmic z-buffer
The only way to write true linearized depth is to use the depth out semantic in the pixel shader, which turns off Z compression, Early Z, Hi-Z and other optimization algorithms employed by the GPU. And by the way, if you’re going to have all those disadvantages, you’re better off with logarithmic z-buffer whichs has insanely high precision.
保守光栅化
保守光栅化说起来很简单,手动实现原理也一目了然,但是实现起来却很操蛋。好在线代硬件已经直接支持保守光栅化了,硬件只需要在 光栅化的时候稍微调整一下覆盖策略就能实现。
所以也许这个部分的内容有些过时,但作为参考。
概念
所谓保守光栅化就是保守地光栅化,我们知道一般的光栅化为了防止重复着色一个像素采用了顶点覆盖像素cell中心才着色。而所谓保守光栅化则是,保证一个像素完全被覆盖或者只要一个像素被覆盖就着色。前者叫做低估保守,后者叫做过估保守。这里我们主要讨论的是过估保守,之后所说的所有保守都是过估保守。
为什么需要过估保守,因为有的时候基于GPU的计算要求不要漏掉任何潜在的测试集。举个简单的例子就是像素碰撞检测,如果使用传统的光栅化来做粗碰撞检测,无疑会漏掉一些碰撞的对象。而采用过估保守光栅化,就不存在这个问题。
虽然现代API(D3D11.3、D3D12)都是硬件实现的保守光栅化,但是研究一下如何手动实现保守光栅化依然具有意义。
一般的思想是处理以下三种基本简单情形:

思想就是把每条边都沿着xy轴向外各偏0.5个像素宽高单位。这样就保证了这个包围多边形是一个最优的一定在标准光栅化下着色所有原三角形相交像素的多边形。
平面一般方程: 可按照点法式推出。
在GPUGem2上有两种算法,思路都差不多。第一种是使用上述思想制造一个最优包围多边形。另一种是因为当年没有GS所以直接传了9个顶点到VS为了优化这种多顶点的情况,将原先的多边形变为三角形再输出,然后再PS中进行相交测试,于是第一步变成了直接使用视点和平移边形成的平面的交线,根据这个交线用其次坐标求出xy方向的坐标。
这两种算法,作者没有考虑z值,因为在近裁剪面距离视点比较小的时候,像素平移像素的距离并不会引起大的深度变化,而是和近裁剪面的距离有关,而这个距离本身就会极大地影响光栅化精度。而且原本标准的中心覆盖光栅化结果也并非有完全精确的深度。
正常来讲我们只要理解保守光栅化只是改变了一种光栅化覆盖像素的判断方式,就不会再纠结于上面算法忽略深度的做法了。
原本的覆盖判断方式是,覆盖中心;
而现在是只要有覆盖。
但是,手动保守光栅化实际上确实是改变了原来的直线边,这和直接改变覆盖方式确实不一样。
在现代API上,保守光栅化都是通过改变覆盖方式,在硬件上实现的。
现在如果我们要人肉保守有了Geometry shader可以不考虑深度变化,仅仅在GS中变换到Clip空间后直接在xy平面内偏移顶点位置。实现证明确实不会对深度和法线有什么影响。
下面是我使用保守光栅化和不使用的深度图和法线图(200X150分辨率):
保守

非保守

保守

非保守

在GS中我们直接把顶点转换到屏幕空间然后利用边法线来生成包围顶点。这种情形下,我们并没有去太关注绕序,只是简单地按照输入索引顺序顺次计算并添加顶点,然后以一个顶点为中心顺次连接一组三角形。所以最后即使需要背面剔除的三角形,新增的边界三角形并没有被踢出。但这并不影响体素化过程和碰撞检测过程,所以不过多考虑了。
另外,裁剪面附近的三角形没有特殊处理,因此这些地方可能会出错,但是在应用情形下很少有这种情形发生。加上这种情形本身也不那么好检测,所以直接忽略掉。
之后我们会使用手动保守和硬件保守来做一组体素化结果的对比。
当前实现的保守光栅化代码如下:
cbuffer MatrixBuffer:register(b1)
{
matrix m;
matrix v;
matrix o;
};
struct VSIn
{
float3 position : POSITION;
float3 normal : NORMAL;
float2 tex : TEXCOORD;
};
struct VOut
{
float4 position : SV_POSITION;
float3 normal:NORMAL;
float3 color : COLOR;
float2 tex : TEXCOORD;
};
VOut VsMain(VSIn input)
{
VOut output;
float4 mo = float4(input.position,1);
mo = mul(mo,m);
mo = mul(mo,v);
float4 vd = mo;
mo = mul(mo,o);
output.position = mo;
output.normal = mul(input.normal,(float3x3)m);
output.normal = mul(input.normal,(float3x3)v);
output.normal = normalize(output.normal);
output.tex = input.tex;
output.tex.y = vd.z;
output.color = float3(1,1,1);
return output;
}
struct GOut
{
float4 position : SV_POSITION;
float3 normal:NORMAL;
float3 color : COLOR;
float2 tex : TEXCOORD;
};
cbuffer GSBuffer:register(b1)
{
int screen_size_x;
int screen_size_y;
int s;
}
GOut gv[9];
int num[3];
#define POINT 0
void processVertex(VOut vert,float2 n1,float2 n2,int base_idx,
#if POINT
inout PointStream<GOut> stream)
#else
inout TriangleStream<GOut> stream)
#endif
{
float dx = 2.0/screen_size_x;
float dy = 2.0/screen_size_y;
float2 dxy = float2(dx,dy);
float2 a = sign(n1);
float2 b = sign(n2);
if(a.x==b.x&&a.y==b.y)
{
//同一象限
float4 newp0 = float4(a*dxy*vert.position.w+vert.position.xy,vert.position.zw);
GOut v1;
v1.position = newp0;
v1.normal = vert.normal;
v1.tex = vert.tex;
v1.color = float3(1,0,0);
gv[base_idx*3+0] = v1;
num[base_idx] = 1;
#if POINT
stream.Append(v1);
#endif
}
else
if(a.x==-b.x&&a.y==-b.y)
{
//对角象限
float2 nn = normalize(n2) + normalize(n1);
if(length(nn)<0.0001)
{
GOut v1;
v1.position = float4(vert.position.xy + 3*dxy*vert.position.w ,0.5,1);
v1.normal = vert.normal;
v1.tex = vert.tex;
v1.color = float3(1,0,1);
#if POINT
stream.Append(v1);
#endif
}
float2 on = sign(nn);
GOut v1;
GOut v2;
GOut v3;
float4 newp01 = float4(on*dxy*vert.position.w + vert.position.xy,vert.position.zw);
float4 newp02 = float4(a*dxy*vert.position.w + vert.position.xy,vert.position.zw);
float4 newp03 = float4(b*dxy*vert.position.w + vert.position.xy,vert.position.zw);
v1.position = newp01;
v1.normal = vert.normal;
v1.tex = vert.tex;
v2.position = newp02;
v2.normal = vert.normal;
v2.tex = vert.tex;
v3.position = newp03;
v3.normal = vert.normal;
v3.tex = vert.tex;
v1.color = float3(1,0,0);
v2.color = float3(0,1,0);
v3.color = float3(0,0,1);
gv[base_idx*3 + 0] = v2;
gv[base_idx*3 + 1] = v1;
gv[base_idx*3 + 2] = v3;
#if POINT
stream.Append(v1);
stream.Append(v2);
stream.Append(v3);
#endif
num[base_idx] = 3;
}
else
{
//相邻象限
GOut v1;
GOut v2;
float4 newp02 = float4(a*dxy*vert.position.w + vert.position.xy,vert.position.zw);
float4 newp03 = float4(b*dxy*vert.position.w + vert.position.xy,vert.position.zw);
v1.position = newp02;
v1.normal = vert.normal;
v1.tex = vert.tex;
v2.position = newp03;
v2.normal = vert.normal;
v2.tex = vert.tex;
v1.color = float3(0,0,1);
v2.color = float3(0,0,1);
gv[base_idx*3 + 0] = v1;
gv[base_idx*3 + 1] = v2;
num[base_idx] = 2;
#if POINT
stream.Append(v1);
stream.Append(v2);
#endif
}
}
[maxvertexcount(18)]
void GsMain(triangle VOut gin[3],
#if POINT
inout PointStream<GOut> stream)
#else
inout TriangleStream<GOut> stream)
#endif
{
num[0] = num[1] = num[2] = 0;
#if 1
float4 p0 = gin[0].position/gin[0].position.w;
float4 p1 = gin[1].position/gin[1].position.w;
float4 p2 = gin[2].position/gin[2].position.w;
float dx = 2.0/screen_size_x;
float dy = 2.0/screen_size_y;
float2 dxy = float2(dx,dy);
float2 normal01 = cross(float3(p0.xy,1),float3(p1.xy,1));
float2 normal12 = cross(float3(p1.xy,1),float3(p2.xy,1));
float2 normal20 = cross(float3(p2.xy,1),float3(p0.xy,1));
float2 e1 = p1.xy - p0.xy;
float2 e2 = p2.xy - p1.xy;
float2 e3 = p0.xy - p2.xy;
if(cross(float3(-e1,0),float3(e2,0)).z<0)
{
normal01 *= -1;
normal12 *= -1;
normal20 *= -1;
}
//normal
#if POINT
{
GOut vl;
vl.position = float4((p0 + p1)/2 + 0.1*(normalize(normal01)),0.5,1);
vl.normal = float3(1,1,1);
vl.color = float3(0,1,0);
vl.tex = float2(0,0);
stream.Append(vl);
vl.position = float4((p0 + p1).xy/2,0.5,1);
stream.Append(vl);
vl.position = float4((p2 + p1)/2 + 0.1*normalize(normal12),0.5,1);
vl.normal = float3(1,1,1);
vl.color = float3(0,1,0);
vl.tex = float2(0,0);
stream.Append(vl);
vl.position = float4((p2 + p1).xy/2,0.5,1);
stream.Append(vl);
vl.position = float4((p0 + p2)/2 + 0.1*normalize(normal20),0.5,1);
vl.normal = float3(1,1,1);
vl.color = float3(0,1,0);
vl.tex = float2(0,0);
stream.Append(vl);
vl.position = float4((p0 + p2).xy/2,0.5,1);
stream.Append(vl);
}
#endif
//2001
processVertex(gin[0],normal20,normal01,0,stream);
//0112
processVertex(gin[1],normal01,normal12,1,stream);
//1220
processVertex(gin[2],normal12,normal20,2,stream);
GOut fas[9];
int n = 0;
GOut a = gv[0];
for( i=1;i<num[0];i++) fas[n++] = gv[i];
for( i=0;i<num[1];++i) fas[n++] = gv[3 + i];
for( i=0;i<num[2];++i) fas[n++] = gv[6 + i];
#if !POINT
for( i=0;i<n-1;++i)
{
stream.Append(a);
stream.Append(fas[i]);
stream.Append(fas[i+1]);
stream.RestartStrip();
}
#endif
#else
#endif
}
float4 PsMain(VOut input) : SV_TARGET
{
float factor = abs(dot(normalize(input.normal),normalize(float3(0,0,-1))));
return float4(float3(1,1,1)*factor,1);
}
在调试的时候,可以先使用点流让GS输出点来确保生成的顶点是正确的。只需要#define POINT 1就好了。

另外一种方法
把个个边按照1个像素对角外移,然后得到新三角形,在创建一个外移边的AABB,在PS中过滤掉所有AABB以外的像素。
首先算新的顶点:
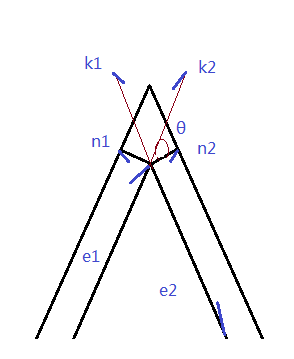
| $\frac{k_1·n_1}{ | n_1 | ^2}·n_1 = n_1$->$\frac{ | k_1 | cos < k_1,n_1 > }{ | n_1 | }=1$->$ k_1=\frac{-e_2}{ | e_2 | } | k_1 | =\frac{-e_2}{ | e_2 | }\frac{ | n_1 | }{cos< k_1,n_1>}$->$k_1=\frac{-e_2l}{ | e_2 | cos <-e_2,\frac{n_1}{ | n_1 | }>} = \frac{e_2l}{e_2·\frac{n_1}{ | n_1 | }}$ |
同理:
| $k_2=\frac{e_1l}{e_1·\frac{n_2}{ | n_2 | }}$ |
因为$k_1,k_2$所夹四边形为菱形,所以:
| $v’ = v + k_1+k_2 = v + l(\frac{e_1}{e_1·\frac{n_2}{ | n_2 | }}+ \frac{e_2}{e_2·\frac{n_1}{ | n_1 | }})$ |
还有种比较巧的方法是使用齐次坐标用空间平面法线叉乘来计算新的顶点,参考GPU Gem 2。
创建AABB就很简单了,把新的顶点不断地迭代,找到最大最小的xy,在我的实现中,我还使用了原三角形的AABB把顶点扩大半个像素长度来strong AABB。
原因在于:对于一个锐角,但是往法线方向平移边得到的顶点可能会遗漏掉顶点所在的区域。
另外有几个实现细节:
- 处理好退化三角形,退化三角形的某一边可能是0,这会导致cross的参数为0向量,从而产生未定义行为。
我简单地把这些边赋予了一个像素的尺寸(然而这种行为并没什么科学根据):
//handle degenerate triangle,ensure there is no zore vector be operated by cross if(length(e1)<0.0001) { e1 = min(dx,dy); } if(length(e2)<0.0001) { e2 = min(dx,dy); } if(length(e3)<0.0001) { e3 = min(dx,dy); } 对于锐角三角形可能会产生相当大偏移顶点值,在输出这些值之前,clamp到[-1,1].否则,D3D11的插值计算将会clip掉NDC以外的部分,直接使用边缘开始插值,从而导致错误的输出位置插值,致使画面产生很多细小的虚线。这回严重印象到体素化。这里其实是因为当时没有给传到PS的顶点位置写noperspective导致插值的时候进行了透视除法得到不正确的结果,但关于D3D11插值的推论可能是错误的。//clamp to void the value which is beyond the [-1,+1] //otherwise a wrong ps attr interpolation could be issue. //正确实现后不需要再clamp // p0n.x = clamp(p0n.x,-1,1); // p0n.y = clamp(p0n.y,-1,1); output.position = float4(p0n*gin[0].position.w,gin[0].position.zw); output.normal = gin[0].normal; output.color = gin[0].color; output.tex = gin[0].tex; output.aabb = aabb; output.vp = p0n; stream.Append(output);- 在很多应用下不能单纯地仅仅只提出背面,所以需要背面检测,在偏移边的时候需要检测背面,否则背面将会反向偏移。这里有个问题,使用叉乘后检测到z(>0)指向背离eye的方向,这时候代表的居然是正面!RS状态为顺时针,左手系全部检查了,不是很清楚是怎么回事。可能和我加载的右手系模型没有变换手性有关!之前那个算法贴的图背面有很多空隙就是因为没有检测背面,导致背面三角形缩小了。
if(cross(float3(-e1,0),float3(e2,0)).z<0)
hl = -hl;
完整的GS和PS:
struct GOut
{
float4 position : SV_POSITION;
float3 normal : NORMAL;
float3 color : COLOR;
float2 tex : TEXCOORD;
//此处需要拒绝透视,AABB本省是关于多个点的所以并不好乘回w
noperspective float2 vp : POSITION1;
nointerpolation int main_axis_index : INDX;
nointerpolation float4 aabb : AABB;
};
struct VOut
{
float4 position : SV_POSITION;
float3 normal:NORMAL;
float2 tex : TEXCOORD;
};
cbuffer GSBuffer
{
int screen_size_x;
int screen_size_y;
float scale;
};
void proc_aabb(float2 pt,inout float4 aabb)
{
if(pt.x>aabb.z) aabb.z = pt.x;
if(pt.x<aabb.x) aabb.x = pt.x;
if(pt.y>aabb.w) aabb.w = pt.y;
if(pt.y<aabb.y) aabb.y = pt.y;
}
[maxvertexcount(3)]
void main(triangle VOut gin[3],inout TriangleStream<GOut> stream)
{
//minx,miny,maxx,maxy
float4 aabb = float4(1,1,-1,-1);
float4 p0 = gin[0].position/gin[0].position.w;
float4 p1 = gin[1].position/gin[1].position.w;
float4 p2 = gin[2].position/gin[2].position.w;
float dx = 2.0/screen_size_x;
float dy = 2.0/screen_size_y;
float2 dxy = float2(dx,dy);
float2 e1 = p1.xy - p0.xy;
float2 e2 = p2.xy - p1.xy;
float2 e3 = p0.xy - p2.xy;
//handle degenerate triangle,ensure there is no zore vector be operated by cross
if(length(e1)<(length(dxy)))
e1 = min(dx,dy);
if(length(e2)<(length(dxy)))
e2 = min(dx,dy);
if(length(e3)<(length(dxy)))
e3 = min(dx,dy);
float2 normal01 = cross(float3(e1,0),float3(0,0,-1)).xy;
float2 normal12 = cross(float3(e2,0),float3(0,0,-1)).xy;
float2 normal20 = cross(float3(e3,0),float3(0,0,-1)).xy;
normal01 = normalize(normal01);
normal12 = normalize(normal12);
normal20 = normalize(normal20);
float hl = scale*length(dxy)*0.5;
if(cross(float3(-e1,0),float3(e2,0)).z<0)
hl = -hl;
float2 p0n = p0.xy + hl*(e1/dot(e1,normal20)+e3/dot(e3,normal01));
float2 p1n = p1.xy + hl*(e2/dot(e2,normal01)+e1/dot(e1,normal12));
float2 p2n = p2.xy + hl*(e3/dot(e3,normal12)+e2/dot(e2,normal20));
proc_aabb(p0.xy,aabb);
proc_aabb(p1.xy,aabb);
proc_aabb(p2.xy,aabb);
aabb.zw += dxy/2;
aabb.xy -= dxy/2;
float2 p0l1 = p0.xy + hl*normal01;
float2 p0l2 = p0.xy + hl*normal20;
float2 p1l2 = p1.xy + hl*normal12;
float2 p1l0 = p1.xy + hl*normal01;
float2 p2l0 = p2.xy + hl*normal20;
float2 p2l1 = p2.xy + hl*normal12;
//make aabb strong
proc_aabb(p0l1,aabb);
proc_aabb(p0l2,aabb);
proc_aabb(p1l2,aabb);
proc_aabb(p1l0,aabb);
proc_aabb(p2l1,aabb);
proc_aabb(p2l0,aabb);
#ifndef DBPOINT
GOut output;
output.position = float4(p0n*gin[0].position.w,gin[0].position.zw);
output.normal = gin[0].normal;
output.color = float3(0,0,0);
output.tex = gin[0].tex;
output.aabb = aabb;
output.vp = p0n;
output.main_axis_index = 0;
stream.Append(output);
output.position = float4(p1n*gin[1].position.w,gin[1].position.zw);
output.normal = gin[1].normal;
output.color = float3(0,0,0);
output.tex = gin[1].tex;
output.aabb = aabb;
output.vp = p1n;
output.main_axis_index = 0;
stream.Append(output);
output.position = float4(p2n*gin[2].position.w,gin[2].position.zw);
output.normal = gin[2].normal;
output.color = float3(0,0,0);
output.tex = gin[2].tex;
output.aabb = aabb;
output.vp = p2n;
output.main_axis_index = 0;
stream.Append(output);
stream.RestartStrip();
#endif
}
float4 main(GOut pin) : SV_TARGET
{
float4 aabb = pin.aabb;
float2 pos;
pos = pin.vp;
if(pos.x<aabb.x||pos.x>aabb.z||pos.y<aabb.y||pos.y>aabb.w) discard;
float3 n = pin.normal;
float3 cc = abs(dot(n,normalize(float3(1,1,1))));
return float4(cc,1);
}
应用
GPU碰撞检测以及体素化的时候都需要执行保守光栅化以免遗漏像素。
##